printf and parallel code debugging¶
I recently spent a lot of time reviewing the code of students that learn how to develop parallel programs in C.
These programs are often buggy, and some students rely on printf to see what happens in their parallel code.
However, the messages obtained this way are misleading in many cases, as what is printed may not representative of what has been executed on the machine.
This post explains why and gives tips to make quick&dirty debugging with printf great again if you insist in not using a debugger (or if you don’t have debuggers on your university’s computers 😅).
Misleading printf calls example¶
The toy program we will play with today is timidly named program and is made to highlight the printing errors you are likely to see with a code written by a student.
program has the following features.
Process parallelism: The program spawns a finite small number of processes. Here, 10 processes are created by the initial process (the initial process prints nothing unless a system error has occurred).
Action determinism: Unless a system error occurs (e.g., cannot create a process), the program will always issue the exact same actions regarding
printfcalls. Here the actions are independent: Each sub process simply prints its number (from 0 to 9) followed by a newline as a singleprintfcall.Action order non-determinism: No guarantee on the order of the parallel actions.
program¶int main(void) {
for (int i = 0; i < 10; ++i) {
switch(fork()) {
case -1:
// fork error -> print some error and exit
case 0:
// 1. there is uncertainty on what the sub process does here.
// we are 100 % sure that it does not crash nor enter an infinite loop.
// we are also 100 % sure that the sub process does not:
// - spawn any processes or communicate with other processes
// - print anything with stdio functions
// 2. we are 100% sure this code is reached.
// all sub processes call printf.
printf("%d\n", i);
// 3. there is uncertainty on what the sub process does afterwards.
// some sub processes do nothing, some execute some code,
// some crash (e.g., segfault), some abort...
// 4. finally, the sub process stops its execution.
}
}
// exit the initial process
}
Each execution of the program therefore calls printf the same number of times, and the content of the messages is the same. Only the order of the printed messages should change.
Here are two consistent executions of the program executed directly from my terminal by calling ./program. The environment I used is composed of kitty 0.26.2, zsh 5.9, NixOS 22.05, Linux 5.15.72, glibc 2.34.
0123456789(newlines omitted): All 10 messages are printed in classical order.0341256789(newlines omitted): All 10 messages are printed but in another order.
If you repeat the execution of the program, you’ll very often see a display of inconsistent messages.
102346578(newlines omitted):9is missing but we are 100% sure thatprintf("9\n")has been executed.012345679(newlines omitted):8is missing but we are 100% sure thatprintf("8\n")has been executed.
Now let us say that you want to automate the counting of the number of bytes written by the program.
This can be done by piping the result of the program to wc, for example ./program | wc -l.
If you do so, you always get either 0, 1 or 2.
So, to wrap things up…
You are sure that your program always executes
printf10 times.When you run it directly in your terminal, it is common that some messages are lost, that is to say not printed on your terminal.
When you pipe the output of your program to another program, almost all messages are lost…

What program does from a system perspective¶
From a system perspective, what program does should be very simple.
Most of its code should consist in communicating with the operating system, which is done via syscalls.
Syscalls (or system calls) are the main mechanism to enable user space processes to communicate with the kernel.
From the user process point of view, a syscall can be seen as a synchronous function call: The user process issues a syscall with some data, then waits for the function to return, then reads what the function has returned.
The main difference with an usual function call is that the function code is not in user space (contrary to a C library that would have been loaded at the program startup time) but in the kernel itself. Code in kernel space is executed with higher privileges. The exact mechanism used to issue a syscall depends on the combination of your CPU architecture and your operating system, but the underlying mechanism mostly relies on interrupts. Interested readers can refer to how to issue a linux syscall depending on your architecture.
Here are the important linux syscalls that we can expect program to issue.
The initial process should issue a syscall to spawn each sub process. Many syscalls can be used for this purpose such as
forkor aclonevariant.Each sub process should issue a syscall to tell the operating system that a message should be printed on the process standard output. This is typically done via a
writesyscall.All processes (the initial process and the 10 sub processes) should issue an
exitsyscall to end their execution.
To check whether program has the same behavior as the one we just described, we can create a new tiny software that exactly issues these syscalls, then check if the execution of tiny and program are similar.
To make sure that tiny is not bundled with any magical code at loading or exiting time, let us write it without C library.
System calls are actually quite simple to do in x86-64 assembly so let us write tiny in assembly 🙂.
Various resources can be useful to do this, such as section A.2 “AMD64 Linux Kernel Conventions” of System V ABI AMD64 Architecture Processor Supplement, or a list of linux syscalls for x86-64 with their codes and parameters.
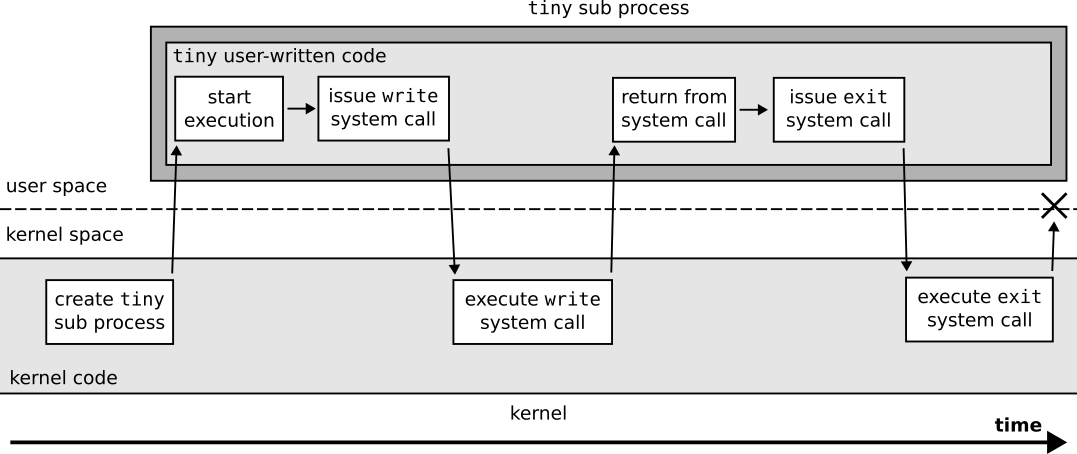
Figuration of the system calls issued by a tiny sub process over time.¶
.text
.global _start
_start:
movq $0, %rbx # loop counter stays in %rbx for the initial process
# main loop of the initial process
L:
# puts counter on the stack so child process can access it
pushq %rbx
# do a fork syscall
movq $57, %rax # syscall number: 57 (fork)
syscall
# fork returns 0 (sets %eax to 0) for the child process
cmp $0, %eax
jz C # child process jumps to C
# (initial process continues without jumping)
# loop until counter is 10
popq %rbx
incq %rbx
cmp $10, %rbx
jnz L
jmp E # exit initial process
# child process "entry point"
C:
# top of the stack already contains the parent counter
# this code sets the top of the stack to counter + 48 ('0')
# so that it contains an ascii value between '0' and '9'
popq %rax
addq $48, %rax
pushq %rax
# do a write syscall
movq $1, %rax # syscall number: 1 (write)
movq $1, %rdi # arg: write on stdout (1)
movq %rsp, %rsi # arg: buffer to write starts on the top of the stack
movq $1, %rdx # arg: buffer is 1-byte long
syscall
# do an exit syscall
E: movq $60, %rax # syscall number: 60 (exit)
movq $0, %rdi # arg: status code 0
syscall
If you are running on x86-64, tiny can be compiled with this command: gcc -c tiny.S && ld -o tiny tiny.o.
When we execute tiny directly in our terminal, it always prints the 10 expected messages.
And when it is piped to wc via ./tiny | wc --bytes, it always prints that 10 characters have been generated…
We can therefore see that tiny prints messages consistently, while program does not!
This version of tiny is not perfect though.
First, it does not handle the errors from syscalls at all (fork returning -1 is not checked, write returning 0 or -1 is not checked).
Another problem is that the initial process can exit before some of its children have issued their write syscall.
This can lead to some misleading prints when tiny is automatically executed many times in a row.
tiny from for i in {1..100} ; do ./tiny && echo ; done.¶012356478 # initial process finished and echo printed its newline before the write of 9 has been done
90123456897 # the write of 9 is not lost though, it appears on one of the next lines
This last problem can be fixed by forcing the initial process to wait for the termination of its child processes, for example by calling the wait4 syscall until it returns -1. This is exactly what tiny-wait does, whose code difference over tiny.S is highlighted below.
This new version (tiny-wait, that can be compiled with gcc -c tiny-wait.S && ld -o tiny-wait tiny-wait.o) always prints consistent messages, even when its execution is automated in sequence.
tiny-wait.S over tiny.S¶--- /build/1icijd482a2g4lsz9mfd8vy43ngkc9kb-source/src/blog/2022-12-printf-message-loss/tiny.S
+++ /build/1icijd482a2g4lsz9mfd8vy43ngkc9kb-source/src/blog/2022-12-printf-message-loss/tiny-wait.S
@@ -23,6 +23,18 @@
incq %rbx
cmp $10, %rbx
jnz L
+
+ # do a wait4 syscall
+W: movq $61, %rax # syscall number: 61 (wait4)
+ movq $-1, %rdi # arg: wait any child
+ movq $0, %rsi # arg: ignore wstatus
+ movq $0, %rdx # arg: no options
+ movq $0, %r10 # arg: ignore rusage
+ syscall
+
+ # looping until the syscall returns a negative value
+ cmp $0, %rax
+ jns W
jmp E # exit initial process
# child process "entry point"
So, what is the difference between program and tiny or tiny-wait in terms of syscalls?
We can use a tool to trace the syscalls done by a process to observe what program does.
strace is the standard tool to do such tracings.
Calling strace -ff --output=out ./program enables to trace the system calls done by the process spawned by executing ./program, while also tracing all the subprocesses that program spawns — and logs will be separated in one file per process.
Let us say that we could trace an execution that led to inconsistent prints: 120345679 was printed.
The messages are not ordered (0 after 1 and 2) but this is consistent since there is no guarantee on message order.
However 8 does not appear at all and has been lost.
Here are the traces of the sub processes in charge of printing 8 and 9.
printf("8\n").¶exit_group(1) = ?
+++ exited with 1 +++
printf("9\n").¶write(1, "9\n", 2) = 2
exit_group(0) = ?
+++ exited with 0 +++
Conclusion: The faulty process exited without calling write at all!
The operating system works as expected, but something fishy happens in the process that runs program…
Buffering in libc’s stdio¶
Let us look at what happens inside a program sub process during its execution.
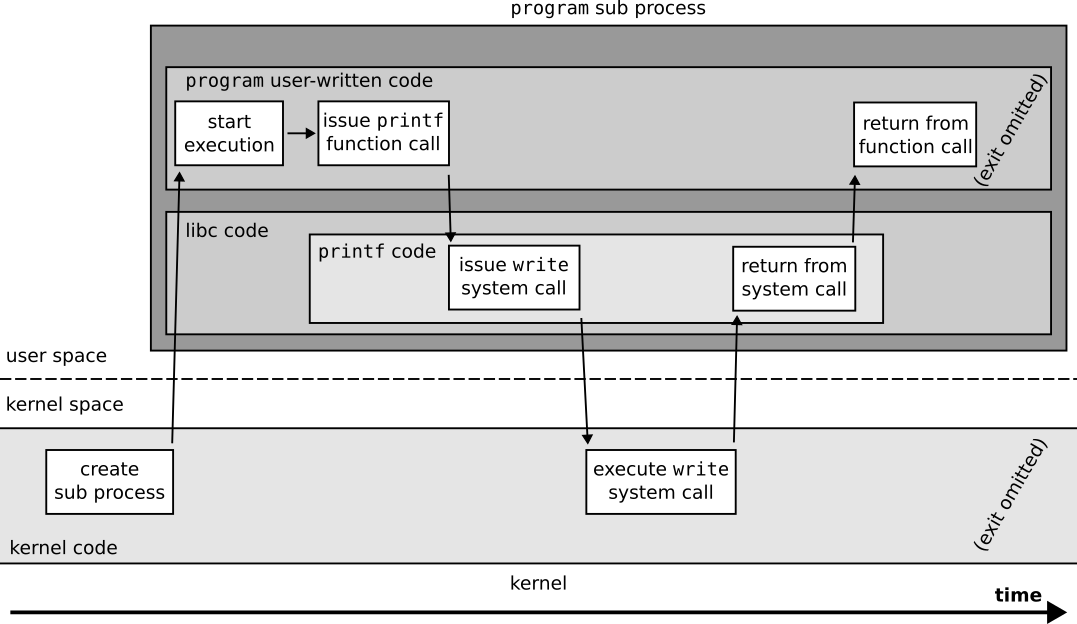
Figuration of the system calls done by a program sub process that write messages.¶
We can see that program sub processes that write messages have a behavior very similar to tiny’s.
The main difference is that the code of the user process is not fully defined by user-written code,
but that some code such as printf is defined in the C standard library instead.
glibc’s printf code is quite complex and does not call write directly.
I do not give details on the various functions that glibc’s printf calls in this post, but interested readers can refer to an hello world analysis for this purpose.
Now let us see what happens for program sub processes that do not write messages.
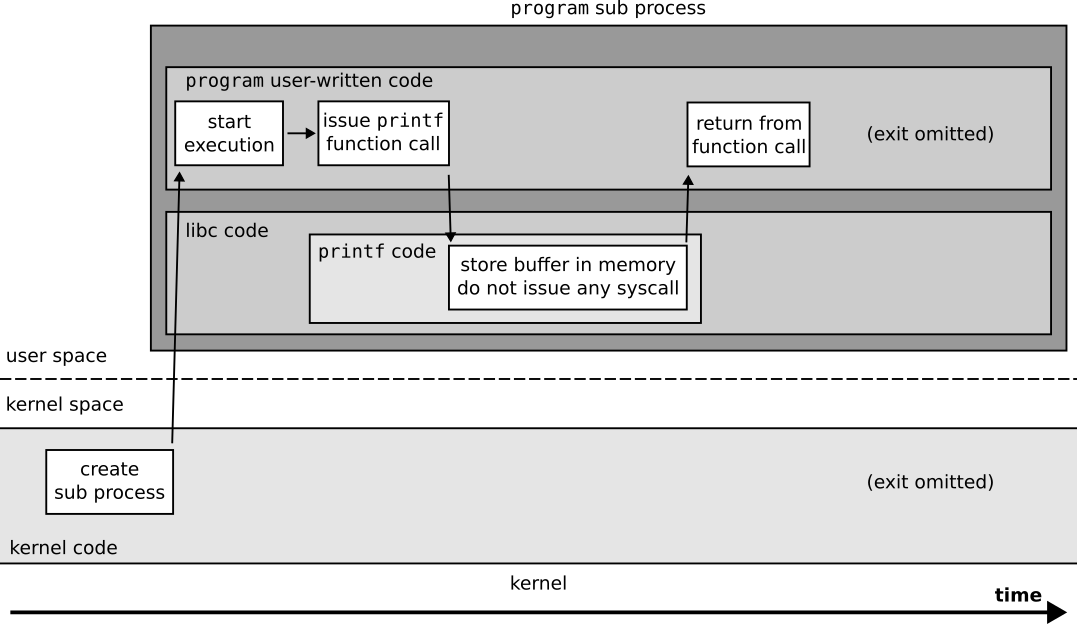
Figuration of the system calls done by a program sub process that does not write messages.¶
The source of our message loss is user space buffering from libc!
man stdio indeed indicates that “The standard I/O library provides a simple and efficient buffered stream I/O interface”.
man setvbuf contains valuable information on the available buffering modes, and defines the default buffering mode of stdout and stderr streams.
man setvbuf.¶The three types of buffering available are unbuffered, block
buffered, and line buffered. When an output stream is unbuffered,
information appears on the destination file or terminal as soon as
written; when it is block buffered, many characters are saved up
and written as a block; when it is line buffered, characters are
saved up until a newline is output or input is read from any stream
attached to a terminal device (typically stdin). The function
fflush may be used to force the block out early. (See
fclose.)
Normally all files are block buffered. If a stream refers to a
terminal (as stdout normally does), it is line buffered. The stan‐
dard error stream stderr is always unbuffered by default.
In addition to this, man exit indicates that “all open stdio streams are flushed and closed” when the exit function from libc is called.
Warning
The exit function from the C standard library should not be confused with the exit linux syscall.
In fact, most linux syscalls are wrapped in function in the C standard library, but these functions can contain user space code that is executed before or after the system call. The libc functions can furthermore decide to use another system call than the one they are named after, for example as of glibc 2.34 the fork glibc function will prefer using a clone syscall variant rather than a fork syscall.
A small experiment¶
Previous section showed that many parameters are important regarding the loss of messages in stdio buffers.
What is behind the standard output of the process?
How does the process terminate?
Have the buffering mode of
stdiostreams been explicitly set by the process?Does the process calls
fflushafter callingprintf?
I propose to define, build and run many variants of program to clarify when messages are lost in stdio buffers.
All the files involved in this experiment are available on this experiment’s gist.
The skeleton that generates the variants is shown below.
It contains the INIT, PRINT, EXIT and FIN macros whose definition depend on the exact variant that is built.
program variants.¶int main(void) {
INIT();
for (int i = 0; i < 10; ++i) {
switch(fork()) {
case -1:
perror("fork");
exit(1);
case 0:
PRINT();
EXIT();
}
}
FIN();
_exit(0);
}
Here are the tested variants for INIT.
nop: do nothing.nbf: explicitly disablestdoutbuffering.lbf: explicitly setstdoutas line buffered, using a buffer of size 1024 bytes.fbf: explicitly setstdoutas fully buffered, using a buffer of size 1024 bytes.
Here are the tested variants for PRINT.
nop: do nothing.p: callprintfoni(without newline).pf: callprintfoni(without newline) then callfflush.pn: callprintfoni\n.pnf: callprintfoni\nthen callfflush.w: call thewritelibc function oni(without newline).wn: call thewritelibc function oni\n.
Here are the tested variants for EXIT.
exit: callexit(0)(clean termination)._exit: call_exit(0)(rough termination: should not flushstdiostreams).segv: issues a segmentation fault (what student code will do in practice 😝).
And finally here are the variants for FIN.
wait: call thewaitlibc function until all sub processes have terminated. Not waiting for the termination of subprocesses is not tested here because it makes the automation of the execution too painful.
You can use the following files if you want to build and run some of these variants yourself.
base.cis the full skeleton codebuild.ninjadefines how to build the variantsgenerate.pygenerates the ninja file
I furthermore propose to execute the processes in several contexts to see how this changes their behavior.
term: call./variantwith standard output set to a terminal.termerr: call./variant 1>&2with standard output and error set to a terminal.file: call./variant > some_file.pipe: call./variant | wc --bytes.
I have executed each variant combination 100 times on a machine of Grid’5000’s cluster Dahu.
For each execution context, I used tmux to log what has been printed on my terminal to a file (by calling tmux commands capture-pane -S - then save-buffer <FILENAME>).
Experiment results¶
The raw traces and usable data files resulting from the execution of all the variants are available on this experiment’s gist.
A first result of this experiment is that the buffering behavior of glibc 2.34 seems deterministic.
For all 336 combinations, there was no variance in the number of messages printed.
In other words, all 100 executions of each variant either printed 10 messages or 0.
To go deeper down the rabbit hole, here is the overall distribution of the messages printed depending on the values of PRINT and execution context.
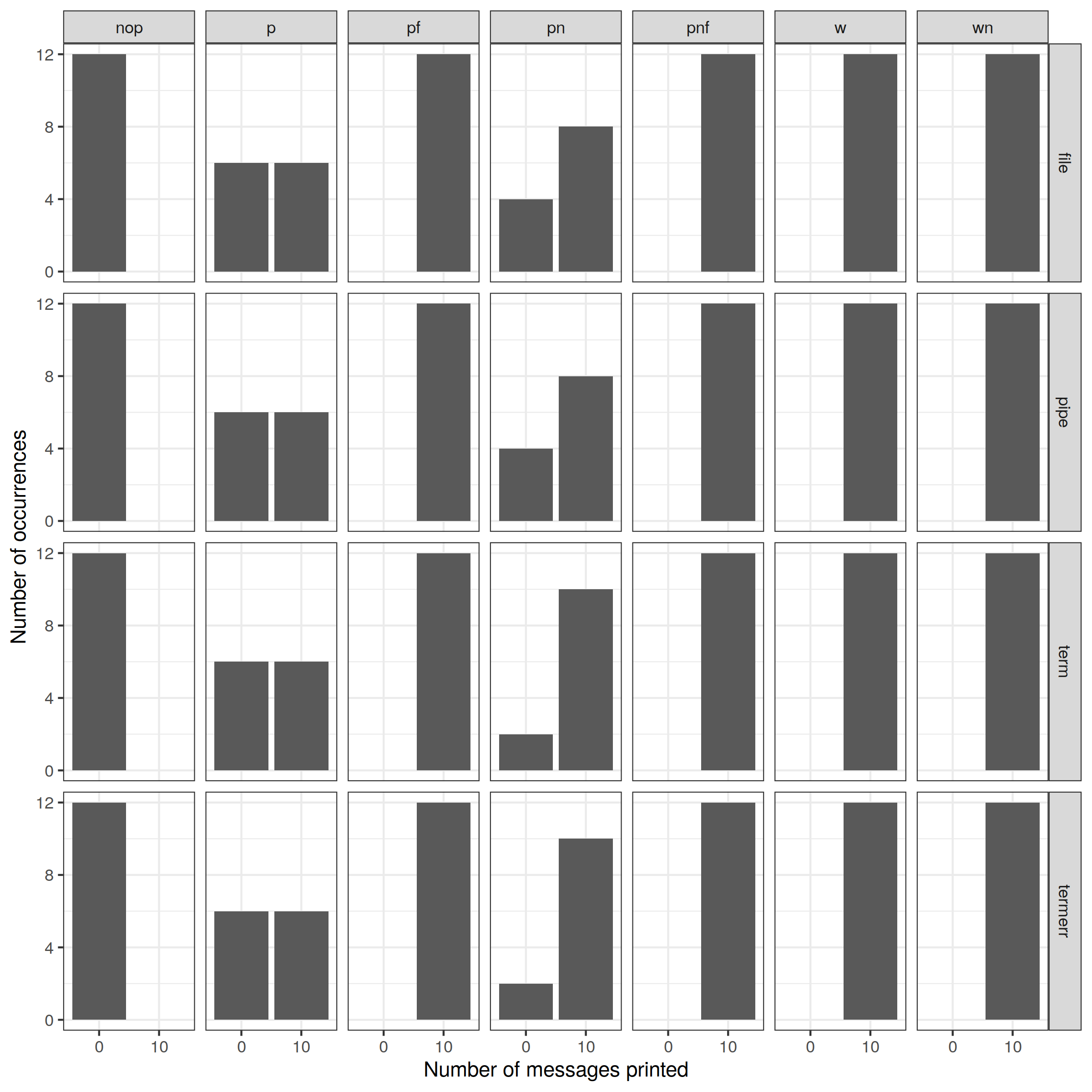
Distribution of the number of messages printed for each variant, depending on how the messages are printed (columns) and on the execution context (rows).¶
We can already conclude for some PRINT strategies.
Not calling any printing function (
nopcolumn) never prints any message. Yay! 😅Calling the libc
writefunction never loses messages, regardless if the buffer is terminated by a newline (wncolumn) or not (wcolumn). 🥳💪Calling
fflush(stdout);after aprintffunction never loses messages, regardless if the buffer is terminated by a newline (pnfcolumn) or not (pfcolumn). 🥳💪Just calling
printfwith a buffer not terminated by a newline (pcolumn) leads to message loss in some cases.Contrary to popular belief, just calling
printfwith a buffer terminated by a newline (pncolumn) also leads to message loss in some cases. 😱
Let us investigate what happens for the non-trivial variants! First, let us zoom on what happens when just calling printf without newline (p PRINT variant).
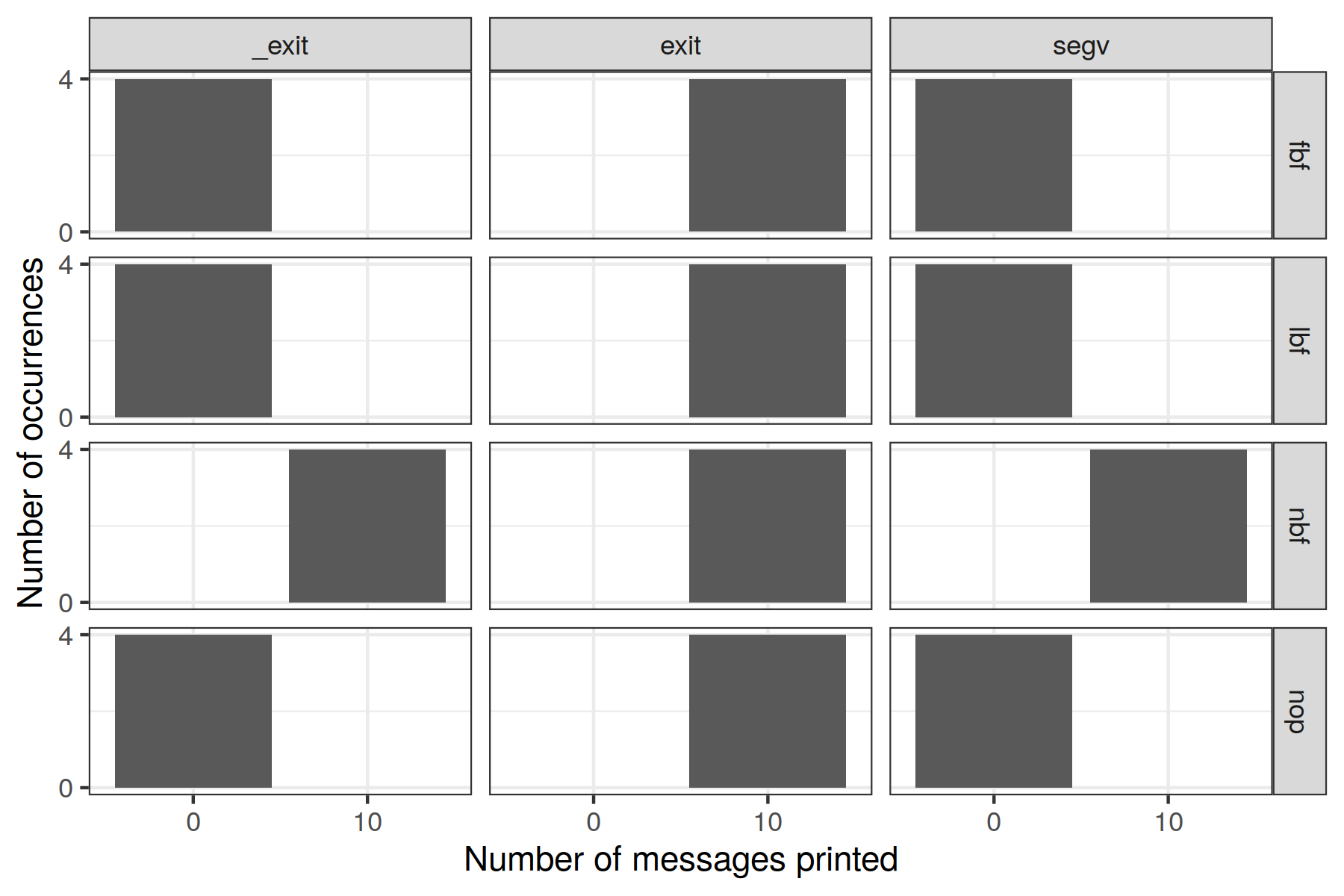
Distribution of the number of messages printed for the print variant where printf is just called without a newline in its buffer. Various combinations exist depending on other parameters and are displayed depending on how the process has set its buffering policy (rows) and how it has terminated (columns).¶
This figure is enough to conclude about just calling printf without newline at the end of the buffer!
If the process terminates by calling the libc
exitfunction, it never loses messages. This is consistent withman exit, which states that the function should flush all buffers.If the process disables buffering on its standard output (i.e., sets
stdoutto the unbuffered buffering mode), it never loses messages. This is consistent withman setvbufthat states that “When an output stream is unbuffered, information appears on the destination file or terminal as soon as written”.In all other cases, the messages are always lost. This is consistent with
man setvbufas the message does not contain a newline for the line buffered policy, and as the message is too small to reach the block size for the block buffered policy.
Let us now finally investigate the last print case: Just calling printf with a buffer terminated by a newline.
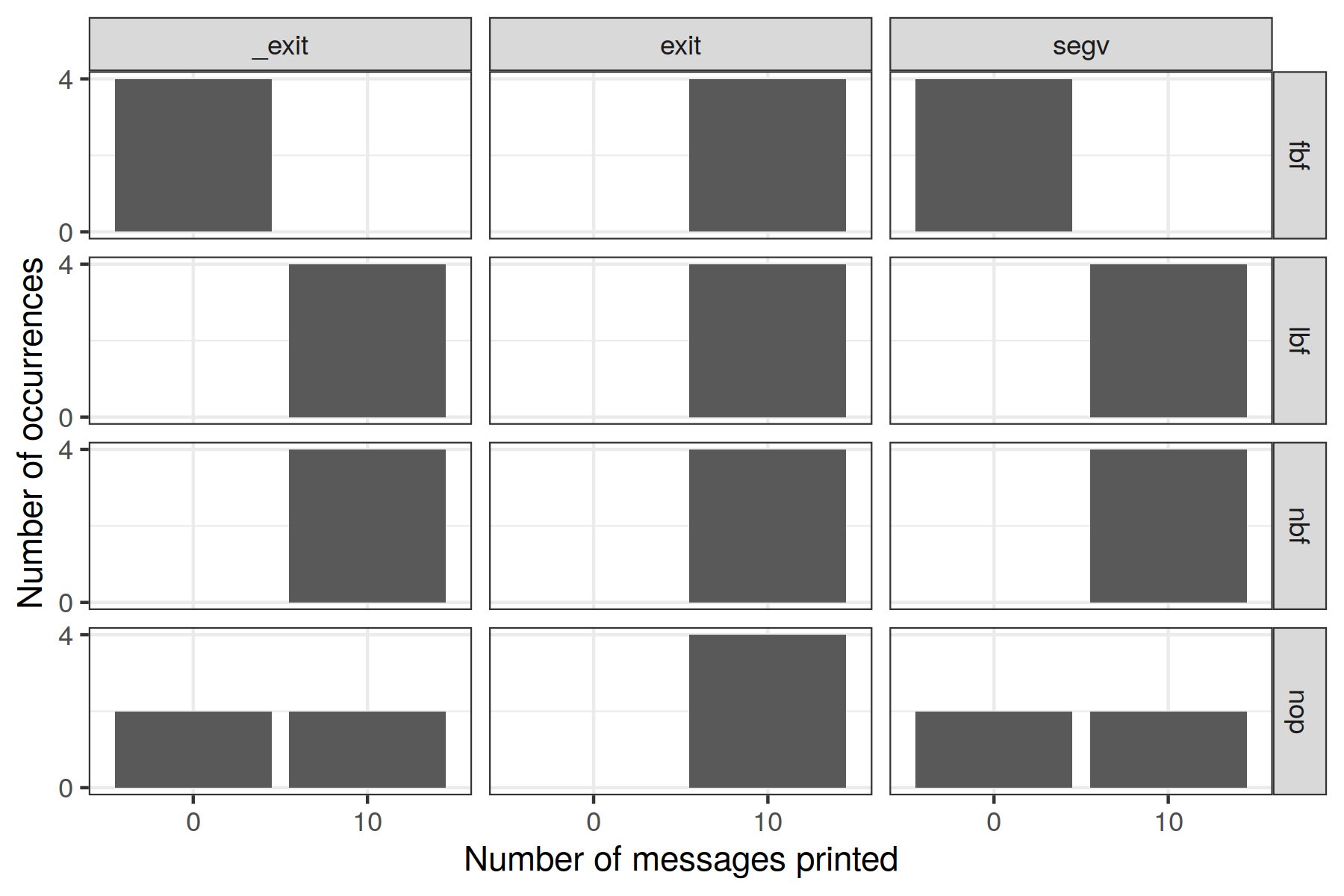
Distribution of the number of messages printed for the print variant where printf is just called with a newline in its buffer. Various combinations exist depending on other parameters and are displayed depending on how the process has set its buffering policy (rows) and how it has terminated (columns).¶
Let us first focus on the cases where the buffering policy is fully defined — all rows but the last one nop.
As expected, if the process terminates by calling the libc
exitfunction, it never loses messages.Messages are never lost if the buffering policy is set to unbuffered (disabled) or line buffered. This is consistent with
man setvbufthat states “when it is line buffered, characters are saved up until a newline is output or input is read from any stream attached to a terminal device (typically stdin)”.As expected, if the file is fully buffered, all messages are lost unless the
exitlibc function has been called. This is because the buffer we wrote is too small to reach the block size we have set.
Finally, we can see that if we do not explicitly set the buffering policy of stdout in our program, messages may be lost or not.
This is because the tested execution contexts here do not have the same default buffering mode, as shown on the next figure.
Files and pipes are block buffered by default, while the terminal is line buffered by default.

Distribution of the number of messages printed for the print variant where printf is just called with a newline in its buffer, and when the default buffering policy is used. Data is shown depending on the context the process has been executed in (rows) and how it has terminated (columns).¶
Take home tips to prevent printf message loss¶
We have seen that simply calling printf in a multiprocess program can easily lead to the loss of messages, which can be very painful if one wants to use such messages to debug one’s program. When all processes terminate cleanly by calling the exit function or similar (e.g., by returning from the main function), no messages are lost. In other cases, typically when at least one process crashes or deadlocks, messages can be lost unless:
You ensured that all
printfcalls were followed by a call tofflush(stdout);.You ensured that buffering on
stdouthas been disabled. If you can change the source code of the program you execute, you can disable buffering manually by callingsetvbuf(stdout, NULL, _IONBF, 0);at the beginning of your program. If you cannot or do not want to change the program source code, you can use tricks to force the program to execute a similar code at initialization time. For example, the stdbuf executable from GNU coreutils has been created exactly for this purpose. It works by forcing your program to load a dedicated library (libstdbuf.so) at initialization time by settingLD_PRELOADbefore issuing anexecsyscall (cf. stdbuf source code). Thelibstdbuf.solibrary has a constructor, that is to say a code that is executed when the library is loaded (cf. libstdbuf source code). This code essentially callssetvbufaccording to the command-line arguments given tostdbuf. Details on howLD_PRELOADworks are given in man ld.so.
If you have additional properties on the messages sent to printf (e.g., that they are finished by a newline or that they are big enough), other stdio buffering policies may prevent message loss — but doing such a strong assumption on students’ code is not reasonable IMHO.
Finally, another solution could be to force the use of stderr rather than stdout, as stderr is unbuffered by default.
However this change is not trivial to do: As seen on the experiment done in this post, redirecting the file descriptors of the process before calling it does not help in any way. We could rewrite printf calls to fprintf on stderr with a macro such as #define printf(args...) fprintf(stderr, ##args), but I think that simply adding an setvbuf(stdout, NULL, _IONBF, 0); instruction at the beginning of the main function of a student code that has inconsistent prints would be more convenient and much more reliable.
Acknowledgements, FAQ and misc. stuff¶
Thanks to Raphaël Bleuse, Arnaud Giersch, Michael Mercier, Clément Mommessin, Lucas Nussbaum and Samuel Thibault for their feedback on this post, which has improved its quality.
Question. What is program’s source code? real-program.c
Warning. By default, zsh clears the current line before printing the prompt. This can lead to the loss of messages when the initial process does not wait for its children. This behavior can be disabled by calling setopt nopromptcr in your zsh setup.